

We explore using versatile format information from rich text, such as font size, color, style, and footnote, for text-to-image generation and editing. Our framework enables various controlibility, including intuitive local style control, precise color generation, and supplementary description for long prompts. Check out our paper for more applications.
A pizza with mushrooms, pepperonis, and pineapples on the top.


A Gothic church in the sunset with a beautiful landscape in the background.


A night sky filled with stars above a turbulent sea with giant waves.
Styles: Van Gogh, Ukiyo-e


A close-up photo of a corgi wearing a hat1, beach and ocean in the background.
Styles: Impressionism.
1A lady's hat.


A man in suit1 with a green apple on his face..
1A colorful Hawaiian shirt.


A dog playing guitar on a boat, sailing in the ocean.


A girl with long hair sitting in a cafe, by a table with coffee1 on it, best quality, ultra detailed, dynamic pose.
1Ceramic coffee cup with intricate design, a dance of earthy browns and delicate gold accents. The dark, velvety latte is in it.


A pixel art of a duck with a gun1 in hand, wearing a hat2, minimalist, flat
1A bouquet of flowers.
2A black hat decorated with a red flower.


A watercolor painting of the detective duck wearing a sheriff uniform1 and holding a vintage handgun2.
1A dark green, washed jacket.
2A beautiful flower bouquet made of pink roses.


A kid wearing a backpack riding a bike in a street with fallen leaves.


A panda1 standing on a cliff by a waterfall.
1Happy kung fu panda, asian art, ultra detailede.


A portrait of a man with a golden beard wearing a hat.
Style: Cubism



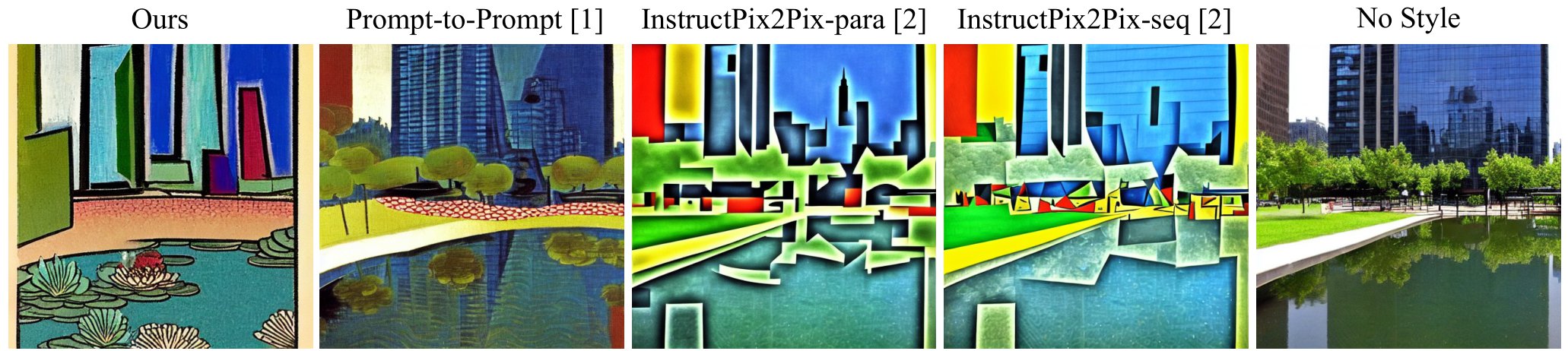
A small pond (Ukiyo-e) surrounded by skyscraper (Cubism).

A night sky filled with stars (Van Gogh) above a turbulent sea with giant waves (Ukiyo-e).

A coffee table1 sits in front of
a sofa2 on a cozy carpet. A painting3 on the wall. cinematic lighting, trending on artstation, 4k,
hyperrealistic, focused, extreme details.
1A rustic wooden coffee table
adorned with scented candles and many books.
2A plush sofa with
a soft blanket and colorful pillows on it.
3A painting of wheat field
with a cottage in the distance, close up shot, trending on artstation, cgsociety, hd, calm,
complimentary colours, realistic lighting, by Albert Bierstadt, Frederic Edwin Church.

The plain text prompt is first input to the diffusion model to collect the self-attention and cross-attention maps. Attention
maps are averaged across different heads, layers, and time steps. The self-attention maps are then used to create the segmentation
using spectral clustering and the cross-attention label each segment.
The rich text prompts obtained from the editor are stored in JSON format,
providing attributes for each token span. According to the attributes of each token, corresponding controls
are applied as denoising prompt or guidance on the regions indicated by the token maps.
We preserve the structure and background from plain-text generation by injecting the features or blending the noised samples.
[1] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv:2208.01626, 2022.
We thank Mia Tang, Aaron Hertzmann, Nupur Kumari, Gaurav Parmar, Ruihan Gao, and Aniruddha Mahapatra for their helpful discussion, code reviewing, and paper reading. We thank AK, Radamés Ajna, and other HuggingFace team members for their help and support with our online demo. This work is partly supported by NSF award no. 239076, NSF grants no. IIS-1910132 and IIS-2213335.
@inproceedings{ge2023expressive,
title={Expressive Text-to-Image Generation with Rich Text},
author={Ge, Songwei and Park, Taesung and Zhu, Jun-Yan and Huang, Jia-Bin},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2023}
}
@article{ge2025expressive,
title={Expressive Text-to-Image Generation and Editing with Rich Text},
author={Ge, Songwei and Park, Taesung and Zhu, Jun-Yan and Huang, Jia-Bin},
journal={International Journal of Computer Vision (IJCV)},
year={2025}
}
{kind=link}
{kind=link}